
previous article:Virtual Directives and Handler Design
In terms of instruction set design, during the process of intermediate code virtualization, which involves earlier transformations and instruction decomposition, a single line of code may correspond to one or multiple virtual instructions. As shown in the diagram below, for example, a simple addition operation 'r2=r1+3;' could be virtualized into four virtual instructions: two load instructions, one addition instruction, and one store instruction.
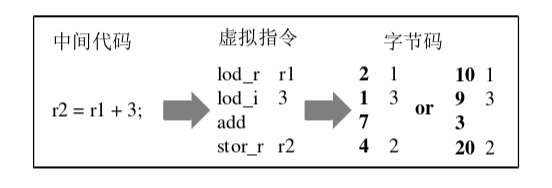
Code virtualization protection ultimately transforms the target code into a bytecode format and saves it in this form. This allows for the concealment of readable information within the instructions and facilitates the reading and interpretation by the virtual interpreter. During the encoding process, virtual instructions are divided into two parts: opcode and operand (some instructions may not have operands). Each virtual instruction is associated with an interpreter responsible for implementing the functionality represented by the instruction. Thus, we assign a unique number to each virtual instruction, which serves as both the opcode and the index ID of its interpreter.
Moreover, we also assign numbers to the registers and other storage units, enabling us to encode virtual instructions into specific bytecode programs. As shown in the example in the diagram, the first column represents the opcodes of virtual instructions, and the second column contains their parameters. In practical protection, we can modify the encoding rules to change the mapping relationship between virtual instructions and bytecode. As demonstrated in the two bytecode encoding results above, each protection instance randomly substitutes the mapping relationship between virtual instructions and bytecode. This makes the results of different protections exhibit distinct mapping rules, thereby increasing the difficulty of reverse engineering the virtualization protection.
Furthermore, we can enhance the protection by encrypting the bytecode before storing it. During execution, the interpreter decrypts the read bytecode to obtain the actual opcode, then schedules the corresponding handler based on the decoding, and finally interprets the instruction's semantics and functionality.
JS一键VMP加密 jsvmp.com
